머신러닝 교과서 with 파이썬, 사이킷런, 텐서플로

이 책은 다른 머신러닝 도서가 그렇듯이 인공지능이 어떤 역사를 가지고 발전했는지로 이야기를 시작합니다. 머신러닝에서 사용되는 전반인 용어와 표기법에 대한 정의로 글을 시작하기 때문에 입문서로 큰 장점이라고 생각됩니다. 입문서라고 나온 도서들 중에도 번역된 용어와 원어가 혼재되어 사용되어 인터넷에서 얻는 자료와 용어차이에서 오는 괴리감이 있는데 이 책은 그 부분을 해결 해주는 부분이 있습니다.
파이썬에 익숙하지 않은 사용자를 위해서 패키지 관리를 위해 pip와 conda에 대한 사용법도 제시하고 있습니다. 하지만 파이썬 문법에 대한 설명이 없기 때문에 파이썬은 어느 정도 익힌 다음에 읽는 것을 추천합니다.
2장부터는 실제적인 실습으로 들어갑니다. 퍼셉트론으로 시작해서 익숙하지 않았던 아달린 모델 등 프레임워크를 이용하지 않고, numpy와 sklearn을 이용해서 코드를 작성하기 때문에 PYTHON에 익숙해지고 머신러닝의 개념을 잡기에 좋은 구성이라고 생각합니다. 수학 또한 어떤식으로 유도가 되고 어떻게 적용이 되는지 알려주기 때문에 수학적으로 탄탄이 갖출 수 있는 책입니다.

처럼 수식을 통해서 설명을 하고 있어서 느낌적으로 이해 하는 것이 아니라 실제적으로 어떤 과정을 통해서 유도 하는지 보여주고 있습니다
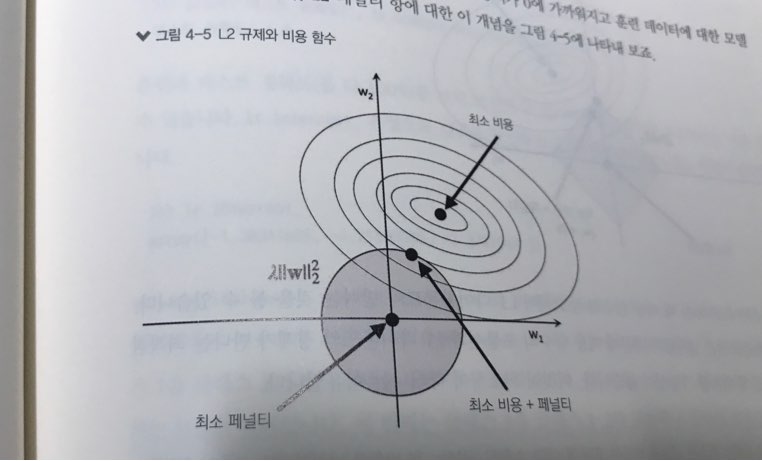
기하적으로 어떤식으로 규제와 Loss가 사용되는지 보여주기 때문에 다른 책을 통해서 봤을 때 이해가 되지 않던 부분이 명확지는 느낌을 받을 수가 있습니다.
import numpy as np
class Perceptron(object):
def __init__(self, eta=0.01, n_iter=50, random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
def fit(self, X, y):
rgen = np.random.RandomState(self.random_state)
self.w_ = rgen.normal(loc=0.0, scale=0.01, size=1+X.shape[1])
self.errors_ = []
for _ in range(self.n_iter):
errors = 0
for xi, target in zip(X, y):
update = self.eta * (target - self.predict(xi))
self.w_[1:] += update * xi
self.w_[0] += update
errors += int(update != 0.0)
self.errors_.append(errors)
return self
def net_input(self, X):
return np.dot(X, self.w_[1:] + self.w_[0])
def predict(self, X):
return np.where(self.net_input(X) >= 0.0, 1, -1)
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data', header=None)
df.tail()
| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | Iris-virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | Iris-virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Iris-virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Iris-virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Iris-virginica |
import matplotlib.pyplot as plt
y = df.iloc[0:100, 4].values
y = np.where(y == 'Iris-setosa', -1, 1)
X = df.iloc[0:100, [0, 2]].values
plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='x', label='versicolor')
plt.xlabel('sepal length [cm]')
plt.ylabel('petal length [cm]')
plt.legend(loc='upper left')
plt.show()
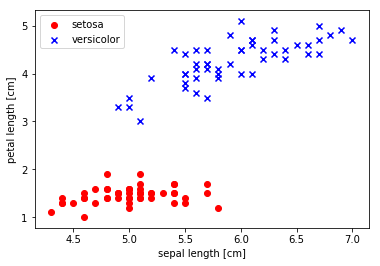
Jupyter Notebook을 이용해서 실습을 진행해 Jupyter Notebook에 대한 사용법도 익힐 수 있습니다.
이렇게 역사를 훑고 난 뒤에는 많이 쓰고 있는 모델인 logistic regression, SVM, 결정 트릭, KNN 등을 예제 코드와 함께 공부 할 수 있습니다. 코드만 있거나 설명만 있는 구조가 아니라 설명과 함께 전체 코드를 짜보면서 할 수 있습니다. 코드는 GitHub을 통해서 제공 되기 때문에 오타 등으로 인해서 다른 결과가 나오는 것을 쉽게 잡을 수 있고, 코드 분석을 책에 있는 것보다 편하게 할 수 있습니다.
데이터 셋을 만들고 가공하는 법에 대한 것도 한 장을 크게 할애하고 있습니다. 머신러닝의 핵심 요소 중 하나인 차원 축소를 위한 알고리즘에 해당하는 주성분 분석, PCA 등의 알고리즘 설명이 충분히 있습니다.
저수준 API까지 잘 설명이 되어 있습니다. tensorflow 2.0이 나오면서 변경 된 변경점들을 이전 버전과 비교 해주고 있기 때문에 인공지능에 입문하려고 고민하면서 책을 찾고 있다면 좋은 책입니다. 교과서라는 책 이름 처럼 차근차근 쌓아 나갈 수 있기 때문에 머신러닝 입문서를 찾고 있다면 추천할 만한 책입니다.
본 리뷰는 길벗에서 책을 제공받아 작성된 리뷰입니다.